Hold on to your slide rules, folks. My next few blog posts are going to get nerdy.
Here’s a picture:
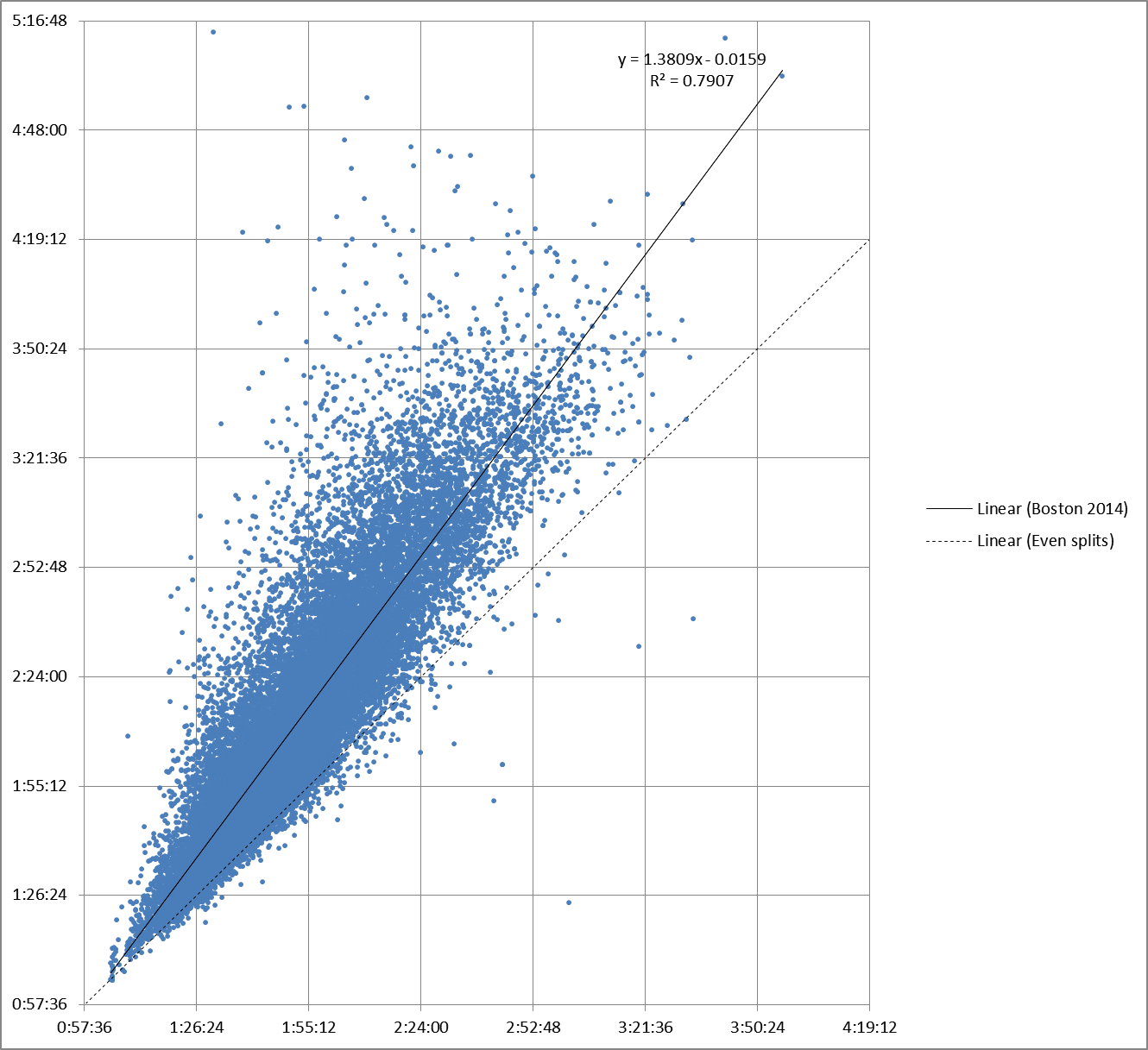
Click to enlarge
This chart graphs the first half splits (on the horizontal, or X, axis) vs. the second half splits (on the vertical, or Y, axis) for runners in the 2014 Boston Marathon.
The data covers about 94% of the finishers. The missing results are scattered randomly, so for all practical purposes this chart can be used to represent the entire field.
Any analysis of this data, to be more than just playing with numbers, should be designed to reveal information that might help you become a better runner. But I do like playing with numbers, so let’s start with the basics and go from there, shall we?
The dashed line on the chart represents even splits. Any runner below the line ran Boston with negative splits, faster over the second half than the first. Anyone above the line ran positive splits – slower in the second half of the race.
The first, and most obvious, conclusion we can draw from the chart is that many, many people, most of the field, ran positive splits at Boston this year. This is in spite of the commonly held opinion that to run your best race, you should run even splits, with your first half as close to the second as you can manage.
The solid line is the result of running a linear regression (using Microsoft Excel) on the data to find the straight line that is the best fit. As you can see from the formula, that line has a slope of about 1.38. In other words, for a “typical” runner, every extra minute in the first half means an extra 1:23 in the second half.
R2 is a measurement of how closely the data matches the regression line. In this case, it measures how accurately you can predict a runner’s second half split by knowing their first half split. R2 can range from 0 (not at all) to 1 (perfectly). The value of .79 for this particular regression means it’s a pretty good fit.
How much is of the difference between the first and second halves was due to the course?
Boston’s notorious hills come in the second half, but the last 10K is a fast, mostly flat or slightly downhill roll to the finish.
The splits from an “even effort” pace calculator that allows for changes in the terrain show the second half as only slightly slower. According to the calculator, the contours of the course will create a positive split of about 2 minutes and 30 seconds for a 3:10 marathoner. Extend that over the complete range of finish times, and the calculator indicates that for our “typical” runner, every extra minute in the first half means an extra 1:01 in the second half. That leaves 22 seconds unaccounted for.
Heat slows a runner down. How much of the difference was due to temperature?
Boston 2014 started out cool. It was near 50 degrees in Hopkinton when the gun went off for the first runners. But it was a bright, sunny day, and temperatures warmed up into the 60’s by the time the last runner crossed the finish.
One study states that the ideal temperature for the average runner is in the low 40’s. At 50, that average runner loses about 1% of their speed, while at 60, it’s about 4%. We have to make a few assumptions here, but it’s not unreasonable to assume that the rise in temperature might turn a 4 hour marathoner into a 4:07 marathoner, or a 2 hour first half into a 2:03:30 second half.
In big, round numbers (we ignored a lot of variables), our “typical” runner lost about two more seconds for every additional minute compared to their first half time due to the temperature.
That still leaves us with 20 seconds unaccounted for.
How much of the difference is because running a marathon is hard? Because normal humans start to slow down after 18 to 20 miles in almost every case? Maybe that 20 seconds is what the typical runner loses in every marathon?
We’ll look into this more… next time!
(Note: I’m figuring this all out as I go along. Comments or questions, especially from people who’ve taken more stats classes, are always welcome!)
Wow! Super cool post. I love the data and don’t care if that makes me a dork. I even-split Boston, but in 2011 when it was arguably one of the best days to run that course in history.
Cool data analysis.
Great dataset. Just a word of caution. The high R2 is probably due to autocorrelation in the error structure (OLS assumes indpendent errors) since you are measuring the same runner twice. But the scatter plot tells its tale anyways.
Well, yes. While correlation != causation, that is the assumption here.
Could you please elaborate on that comment. I agree that correlation!=causation. In fact we can not sort out causation unless we have an experimental setup at hand. My comment was less substantial, pointing to the well known fact that in regressions, autocorrelated error-structures will lead to an upward bias in R2.
First, thanks for your comment. Google can’t replace actual stats classes, no matter how much I try, so it’s good to hear from other people.
(after some Googling 🙂 Isn’t “autocorrelation in the error structure” a fancy way of saying “though correlation doesn’t imply causation, causation does help create correlation”? We’re fine with the fact that for a single runner, first half splits will be similar to second half splits. Aren’t we counting on that to try and tease other information from the data sets?
Or as Wikipedia sez: “Multicollinearity does not reduce the predictive power or reliability of the model as a whole, at least within the sample data themselves; it only affects calculations regarding individual predictors.”
Or maybe I don’t understand any of this well enough yet. If that’s the case, I’d like to fix that.
And if I get to it today, I’ll have an example of how even though the data points represent a single runner’s halves, correlation (measuered by r2) can still be poor.
Pingback: Leituras de 5a Feira | Blog Recorrido
Pingback: Marathon Splits in the Lead Pack | Y42K?
Pingback: A Different Look at the Same Ol’ Data | Y42K?
Pingback: What Are Split Scores? | Y42K?
Pingback: Plotting Split Scores | Y42K?
Pingback: 5K Split Distribution at the 2014 Boston Marathon | Y42K?
Pingback: Another Precinct Heard From: 5K Split Distribution at the 2013 Chicago Marathon | Y42K?
Pingback: Do Women Marathoners Push Themselves As Hard As Men? | Y42K?
Pingback: Marathon 5K Split Distribution by Age | Y42K?
Pingback: 5K splits for Men and Women at the 2013 New York Marathon | Y42K?
Pingback: Average Finish Times by Age and Gender for 2014 Boston Marathon | Y42K?